By Donato Montanari, General Manager and VP, Machine Vision, Zebra Technologies
A recent piece of research by Zebra Technologies found that among machine vision leaders in the automotive industry, almost 20% in Germany and the UK say their artificial intelligence (AI) machine vision could be working better or doing more. It’s a reminder for machine vision partners to think more deeply about how cutting-edge technology can be optimised for customers. Are there ways that technologies like deep learning machine vision could be more accessible, easier to use, and better deployed within a company? Isn’t it time to overcome the lingering reticence we sometimes hear when it comes to leveraging cloud computing in manufacturing?
We know from the same research that there’s a range of ways manufacturers procure machine vision solutions – solution selection can be made at the site level with sign-off at the corporate level, or selection and sign-off both at the site level to name the two main approaches. And these are underpinned by pricing agreements at the country and regional levels, but less so at a global level.
This ‘site level’ focus has its benefits but can leave room for less desirable variation. There’s always the possibility of different sites using different machine vision solutions for similar workflows, and the possibility of expertise and data not being shared across sites. Even it teams desire it, integration, interoperability and secure data sharing via conventional machine vision systems make things difficult.
Cross-Site Data Challenges
AI, particularly deep learning, thrives on data – volume, variety and velocity of good quality data is key to training and testing deep learning models, so they deliver the outcomes expected when deployed in real life.
Experience and time available can vary between teams and sites, which can create silos and make achieving data quality more challenging. Data needs to be stored, annotated, and used for training models, with other data sets needed for model testing. It makes no sense for company data in these cases to remain siloed, to the detriment of better training for machine vision models.
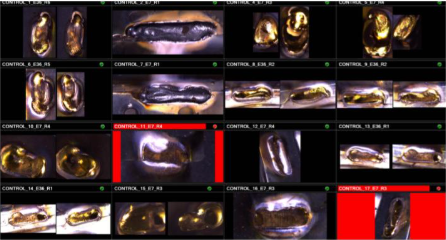
A model trained on a limited set of nearly identical objects won’t perform well when faced with real-world variations. For instance, training a model to recognise defects in a manufactured component can’t rely on 20 images of the same component with slightly different angles. To be effective, 20-50 truly different objects are needed in the training data. These objects need to be distinct, with no shared elements apart from the background, although the whole scene can be subject to site-to-site variations, such as different illumination and/or a different looking conveyor belt.
A deep learning neural network should be exposed to as much variation as possible, including different hours and days of production. A mix of random dates in the dataset is needed which may be inconvenient as it requires data capture over a period of time (unless using a platform for simulating training data), but it’s crucial for training a robust model.
How are manufacturers and their machine vision leaders going to achieve this if they can’t leverage all the data available to them across sites, countries, and regions?
Industrial processes are also subject to various environmental factors, such as changing ambient light, materials with slight variations, vibrations, noise, temperatures and alterations in production conditions. Failing to account for these changes in your training data can lead to reduced model accuracy.
Each site may introduce variations in sharpness, working distance, ambient light, and other factors that the model will learn to handle, so training datasets reflect the full range of variations that the model may encounter in real-world scenarios. If industrial processes involve multiple production sites, it’s a mistake to collect data from only one of them or collect from all of them but keep the data siloed. To fix this, data should be captured and shared from different environmental conditions and production sites—but how?
Another issue with a siloed site approach concerns the annotation of training data for deep learning models. Inaccurate, unclear, and inconsistent annotations inevitably lead to models that do not perform well. It is critical to ensure annotations are precise and unambiguous including across production sites making the same items—but this requires teams to be able to collaborate on annotation projects. Marking different defect types on different images while leaving some defects not marked at all is a common mistake in real-world projects. And what counts as a defect can also be subjective, so cross-validation is important. All defects, regardless of type, should be clearly marked on all relevant images. Again, without taking a unified approach, and leveraging the cloud, the challenge of data annotation among sites and countries remains.
Deep Learning Cloud Platform Solutions
Machine vision teams across manufacturing industries need a new way to commission deep learning machine vision. One of those new ways must be the cloud. A cloud-based machine vision platform would allow users to securely upload, label, and annotate data from multiple manufacturing locations across site, country, and region. A larger, more diverse range of pooled data in a cloud-based platform from across sites and environments is better for deep learning training. Such a platform would allow defined users to work together in real time, collaborate on annotation, training and testing projects, and share their expertise.
Like many industries, manufacturers are faced with hiring and retaining skilled machine vision specialists. Imagine if a company could more easily unlock the skills and expertise of individuals and teams at one site, country or region for the benefit of all, particularly where machine vision talent is harder to find. A collaborative, cloud platform would make this a reality.
A cloud-based solution also delivers scalability and accessibility of computing power. With traditional systems, some select employees get very strong GPU cards in their computers to perform large trainings. With the cloud, every user can access the same high computing power from their laptops. Some costs are generated, but through a pay-as-you-go subscription model, it may still be more beneficial than investing more in a company’s own servers and additional hard-to-find IT personnel.
With a cloud-based platform, users with defined roles, rights and responsibilities could train and test deep learning models in the cloud. Powered by much better training and testing data, they may deliver much higher levels of visual inspection analysis and accuracy beyond conventional, rules-based machine vision for certain use cases. These outcomes are sought by manufacturers in the automotive, electric battery, semiconductor, electronics and packaging industries, to name a few.
A software as a service model would give machine vision teams the flexibility and ease of investing in a cloud-based platform with a subscription while new features, models, and updates are seamlessly added by the technology partner. Deep learning cloud-based platforms will allow for model edge deployment on PCs and devices to support flexible, digitised workflows on the production line, on a PC or device wherever a user or team is located.
AI machine vision leaders want their systems to work better and do more so new ways of implementing, using and deploying the technology is needed, and deep learning cloud-based platforms point the way forward.
Learn more about Zebra’s deep learning machine vision solutions here.